ElasticSearch#
ElasticSearch is a fault-tolerant, high availability, distributed database engine.
This means that the tool can be used to store, index, filter and show data. It is designed to continue operating despite equipment failure, as it can be organized as a “nodes network”. That is, the same database can be copied in multiple computers connected to the network, and the data they contain may be shared among these nodes, either fully or in data shards (also named shards).
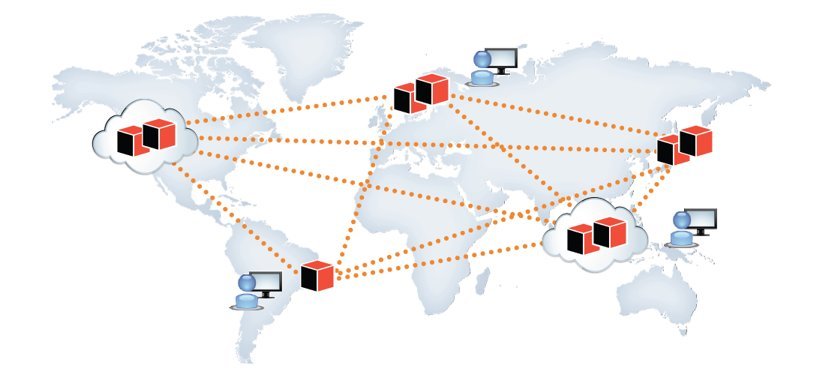
This distributed architecture enables an ElasticSearch database to continue working even when one or two computers composing the network (nodes) stop working. It also allows the nodes to be in different physical locations to achieve a constant speed for the same system in different locations.
In the same way ElasticSearch distributes information, it also distributes the data query processing. When we make a database search and this information is distributed, each node has the task of processing this query and return the available information. In the end, the system as a whole will create the final result, joining the segments given by each node.
For this reason, a system based in ElasticSearch and appropriately configured can make complex queries with large amounts of data, and still keep a high performance for the final user, regardless their location.
ElasticSearch Concepts#
Cluster#
A cluster is a set of nodes in ElasticSearch, it can have one or more nodes. A cluster will have a unique name, and the nodes will recognize the cluster they belong to by its name. It is completely possible to have a cluster with just one node. This is much simpler to configure and this is why it will be chosen as example in this manual.

Node#
A node is an ElasticSearch “server”, it commonly means one computer. Each node will have a unique name in the cluster.
Index#
In ElasticSearch, databases are known as Indexes. One of them works similarly to the old library Indexes and it contains references to a set of documents that share certain characteristics. An index also has a unique name, and we may define or not the documents’ characteristics before adding the documents.
For example, we can have a “customers” index, which makes reference to a set of documents with a store’s customers’ personal data. All of them will have a name, address, age, etc.
In the same way, we can have in the same ElasticSearch cluster a “products” index, which will contain documents describing each product being sold in this store.
We can make queries and updates to these Indexes as well as adding or deleting data from them by using the corresponding name.
Document#
The Elastic Search’s information base unit is the Document. They are stored in JSON format, which makes it more flexible and simple to save any type of data.
We “index data” or “index documents” when we “save data” in ElasticSearch database.